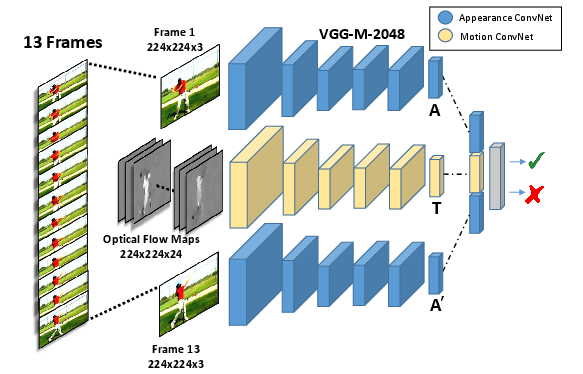
Abstract
Human actions are comprised of a sequence of poses. This makes videos of humans a rich and dense source of human poses. We propose an unsupervised method to learn pose features from videos that exploits a signal which is complementary to appearance and can be used as supervision - motion. The key idea is that humans go through poses in a predictable manner while performing actions. Hence, given two poses, it should be possible to model the motion that caused the change between them. We represent each of the poses as a feature in a CNN (Appearance ConvNet) and generate a motion encoding from optical flow maps using a separate CNN (Motion ConvNet). The data for this task is automatically generated allowing us to train without human supervision. We demonstrate the strength of the learned representation by finetuning the trained model for Pose Estimation on the FLIC dataset, for static image action recognition on PASCAL and for action recognition in videos on UCF101 and HMDB51.